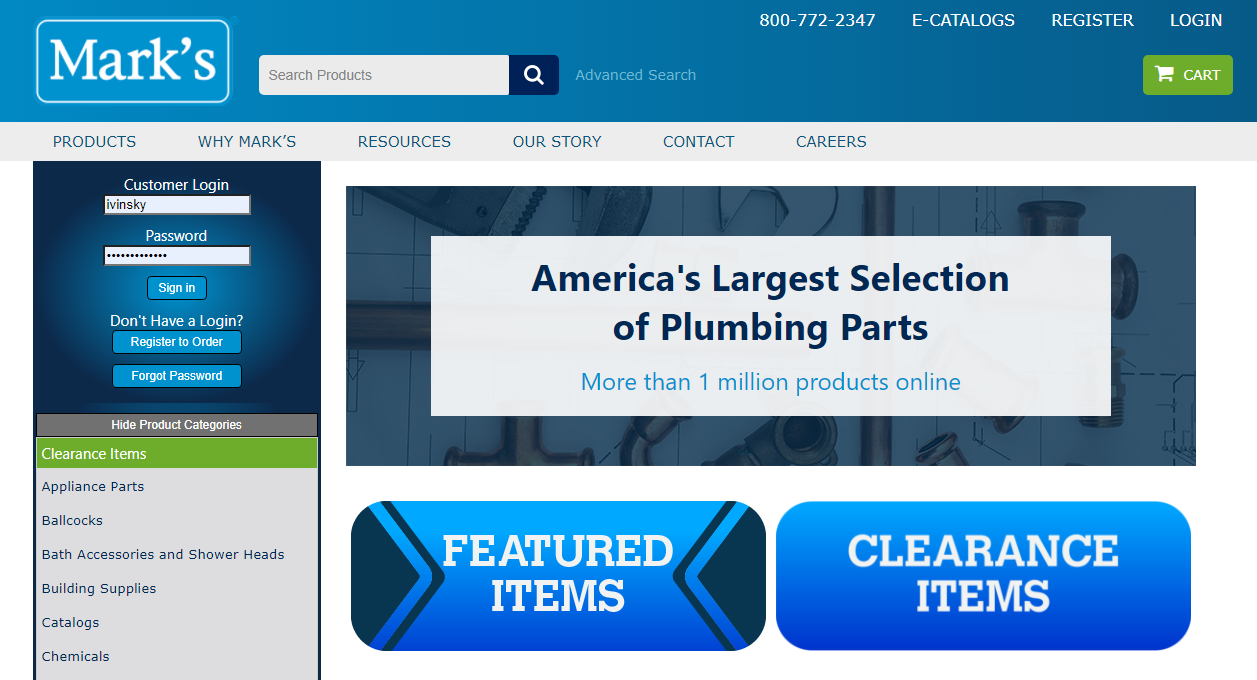
Client's background
The current search and Catalog pages on the website has some issues because of using different DataSources.
Dev Partner Team has been requested to propose and implement Search based solution which will address the pain points associated with the current Catalog(Search/Categories) pages in order to use Solr for search and faceted browsing.
Search Scenario
The requirements and code analysis shows that Mark’s LLC has mainly two kinds of customers:
-
A first group, the “expert” users (e.g. Plumbers, resellers, shops) whose members are querying the system by product identifiers, codes (e.g. GPNumber, VendorPartNumbers, thinks like 100115, SWF000 and CGW175MEMBROIDERY); At least it seems so, they already know what they want and what they are looking for. This kind of scenario, where there’s only one relevant document in the collection, is usually referred to as “Known Item Search”: so our first requirement is to make sure this “product identifier intent” is satisfied.
-
The other group of customers are end-users. Being not so familiar with product specs like codes or model codes, the behaviour here is different: they use a plain keyword search, trying to match products by entering terms which represents names, brands, manufacturer. An here it comes the second requirement which can be summarized as follows: people must be able to find products by entering plain free-text queries. In this case search requirements are different from the other scenario: the focus here is more “term-centric”, therefore involving different considerations about the text analysis we’d need to apply.
While the expert group query is supposed to point to one and only one product (we are in a black / white scenario: match or not), the needs on the other side require the system to provide a list of “relevant” documents, according to the terms entered.
An important thing / assumption before proceeding: for illustration purposes we will consider those two queries / user groups as disjoint: that is, a given user belongs only to one of the mentioned groups, not both. Better, a given user query will contain product identifiers or terms, not both.
Pain Points Addressed
Informed by original discussions with Mark’s LLC, Dev Partner identified several issues of possible improvements.
Issues
- Pages have requests to several DataSources to MsSql DB and Perfion.It can negatively affect website performance.
- From what we see, the search returns all ParIds for specific Keyword or Category from the database and if there are more than a one thousand five hundred products and some filters in the result, the catalogue page rendering takes more than 6 seconds. Solr has facets (filters) out-of-the-box and data for Search results and facets can be taken by using one request
- Google site search doesn't have search log
- The website doesn't have /sitemap.xml and /robots.txt Pages have dynamic data binding from JS model. It appears that Google can't index site pages.
Challenge
The current search and Catalog pages on the website has some issues because of using different DataSources.
Dev Partner Team has been requested to propose and implement Search based solution which will address the pain points associated with the current Catalog(Search/Categories) pages in order to use Solr for search and faceted browsing.
Search Scenario
The requirements and code analysis shows that Mark’s LLC has mainly two kinds of customers:
-
A first group, the “expert” users (e.g. Plumbers, resellers, shops) whose members are querying the system by product identifiers, codes (e.g. GPNumber, VendorPartNumbers, thinks like 100115, SWF000 and CGW175MEMBROIDERY); At least it seems so, they already know what they want and what they are looking for. This kind of scenario, where there’s only one relevant document in the collection, is usually referred to as “Known Item Search”: so our first requirement is to make sure this “product identifier intent” is satisfied.
-
The other group of customers are end-users. Being not so familiar with product specs like codes or model codes, the behaviour here is different: they use a plain keyword search, trying to match products by entering terms which represents names, brands, manufacturer. An here it comes the second requirement which can be summarized as follows: people must be able to find products by entering plain free-text queries. In this case search requirements are different from the other scenario: the focus here is more “term-centric”, therefore involving different considerations about the text analysis we’d need to apply.
While the expert group query is supposed to point to one and only one product (we are in a black / white scenario: match or not), the needs on the other side require the system to provide a list of “relevant” documents, according to the terms entered.
An important thing / assumption before proceeding: for illustration purposes we will consider those two queries / user groups as disjoint: that is, a given user belongs only to one of the mentioned groups, not both. Better, a given user query will contain product identifiers or terms, not both.
Pain Points Addressed
Informed by original discussions with Mark’s LLC, Dev Partner identified several issues of possible improvements.
Issues
- Pages have requests to several DataSources to MsSql DB and Perfion.It can negatively affect website performance.
- From what we see, the search returns all ParIds for specific Keyword or Category from the database and if there are more than a one thousand five hundred products and some filters in the result, the catalogue page rendering takes more than 6 seconds. Solr has facets (filters) out-of-the-box and data for Search results and facets can be taken by using one request
- Google site search doesn't have search log
- The website doesn't have /sitemap.xml and /robots.txt Pages have dynamic data binding from JS model. It appears that Google can't index site pages.
Solution
DevPartner has proposed:
- use Solr Based Search Engine that provides API endpoint for website to get search data by single request
- create console app(Sync) to Index/deindex product and add this App to windows schedule tasks.
- Create index scheme for Solr Engine. The Scheme should support several kinds of customers, 2 kinds of requirements(CONTAINS, FREETEXT and probably Like) and 2 kinds of search
- Rebuild search and Category pages to search documents in Solr index.
- /search?q=keyword page will be used to activate google site search log
- create console App(scheduled task) to generate sitemap.
- Phase 2. The information LastPurchased array should be in cache
Benefits
In addition to optimization of search data workflow, the new model is extensible and will continue to provide means of further integration with other third-party systems as needed for expanding, other enterprise needs(like Highlighting, spell checking, Auto suggesting terms), or rolling out additional ventures.
Project Details
Techniques:
TSQL, .net Framework, .net Core, JavaScript, KnockoutJSPlatform:
SolrTags:
Latest Works

Mark's website
Mark's is USA most knowledgeable team of Plumbing Parts with 30 years experience and more than 1 million products online.
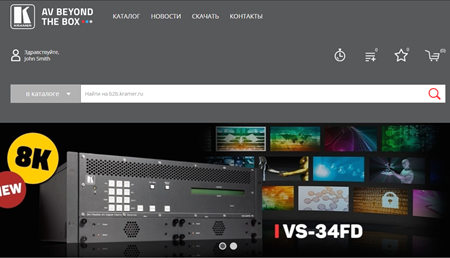
nopCommerce B2B Kramer website
Kramer Electronics Russia. Professional switching equipment for the AV market. Online catalog and B2B platform.
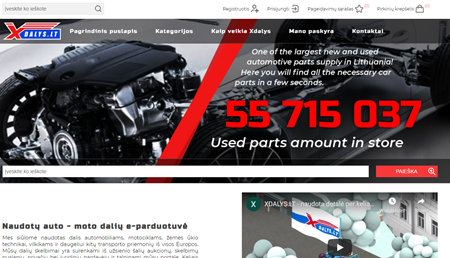
nopCommerce new xDalys website
New website for one of the largest new and used automotive parts supply in Lithuania